Serving MPEG-DASH differs from serving HLS but as long as you have video packaged in ISO BMFF segments, adding an option to also expose content as HLS (HTTP Live Streaming, RFC 8216) is not too difficult.
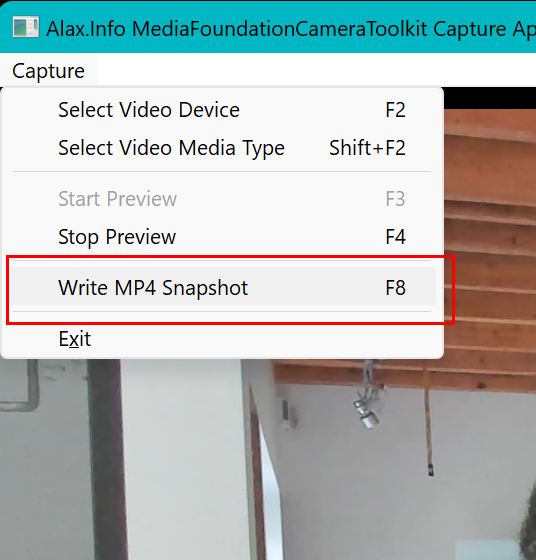
Since the last demo appears to be quite nice, one another addition: ability to drop the internal memory video content of the application into MP4 file.
As the application works and shows video preview, it keeps H.264/AVC version of the data in memory in the form of sliding window. Now you can just hit F8 and have this video – the last two minutes, that is – written into an MP4 file.
What the application does is effectively this: it uses initialization segment from MPEG-DASH content, and concatenates all media segments that the server keeps ready. This way we have an ISO BMFF media file, of the fragmented MP4 flavor. It is playable but not nicely, so the application contintues and then right in the memory and on the fly it re-packages (there is a related bug in Windows Media Foundation which needs to be worked around, but it is what it is) this file into standard MP4 file, using here and there just Windows Media Foundation. This whole process is instant, of course.
And more to this, alternatively you can take this video snapshot even via web server! Just request http://localhost/MediaFoundationCameraToolkit/Capture/video.mp4 and you will have the application to do the same processing and preparation/export of video file, but it will be delivered to browser instead of saving to file system.
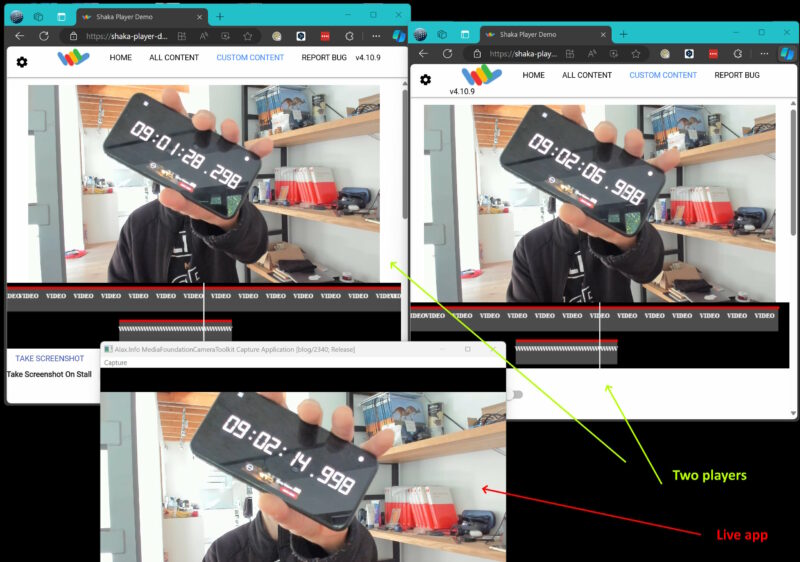
This video camera capture demonstration application features a mounted MPEG-DASH (Dynamic Adaptive Streaming over HTTP) server. The concept is straightforward: during video capture, the application takes the video feed and compresses it in H.264/AVC format using GPU hardware-assisted encoding. It then retains approximately two minutes of data in memory and generates an MPEG-DASH-compatible view of this data. The view follows the dynamic manifest format specified by ISO/IEC 23009-1. The entire system is integrated with the HTTP Server API and accessible over the network.
Since it is pretty standard streaming media (just maybe without adaptive bitrate capability: the broadcasting takes place in just one quality) the signal can be played back with something like Google Shaka Player. As the application keeps last two minutes of data, you can rewind web player back to see yourselves in past… And then fast forward yourselves into future once again.
Just Windows platform APIs, Microsoft Windows Media Foundation and C++ code, the only external library is Windows Implementation Libraries (WIL) if this classifies at all as an external library. No FFmpeg, no GStreamer and such. No curl, no libhttpserver and whatever web servers are. That is, as simple as this:
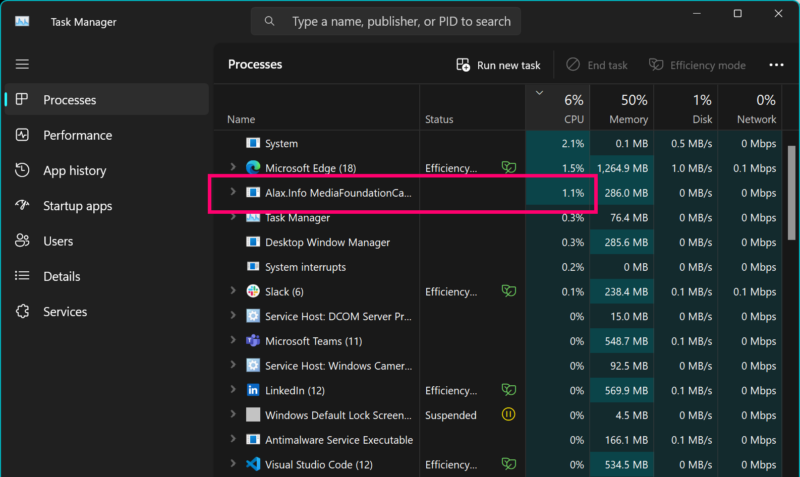
The video is compressed once as video capture process goes, and the application is integrated with native HTTP web server, so the whole thing is pretty scalable: connect multiple clients and this is fine, the application mostly provides you a view into H.264/AVC data temporarily kept in memory within the retention window. For the same reason resource consumption of the solution is what you expect it to be. The playback clients do not evenhave to play the same historical part of the content:
So okay well, this demo opens path to next steps once in a while: audio, DRM, HLS version, low latency variants such as LL-HLS, MPEG-DASH segment sequence representations.
Note that the application requires administrative elevated access in order to use HTTP Server API capabilities (AFAIR it is possible to make it another way, but you don’t need this this time).
The application doing video capture, rendering the 1920×1080@30 stream to the user interface, teeing signal into additional processing, doing hardware assisted video encoding, packaging, serving MPEG-DASH content is not taking too many resources: it is just something that makes good sense.
Oh and one can also use standard C# tooling to display this sort of video signal, here we go with standard PlayReady C# Sample with a XAML MediaElement inside:
In continuation of camera demos, one another build with Microsoft’s Video Stabilization MFT.
In the context of Capture Engine applciation and use of the MFT as an effect, it is used in its defautl configuration, in particular without explicit low latency mode. This creates a noticeable delay in video transmission. Still, it is what it is – the effect still passes through the video feed.
Still, it is hardware accelerated and is apparently well suitable for real-time video processing.
Original implementation is taken from non-realtime denoised and hence the question is how good it is for real time video. Unforutunately, it appears to be rather slow. Essentially, it is a Media Foundation wrapper over…
… with minimal temporal window of three frames sliding one by one. OpenCV implementation could obviosuly be better too, but probably the most efficient improvement would be to take advantage of CUDA variant.
Well, anyway, the demo is here, to see how slow it is for live…
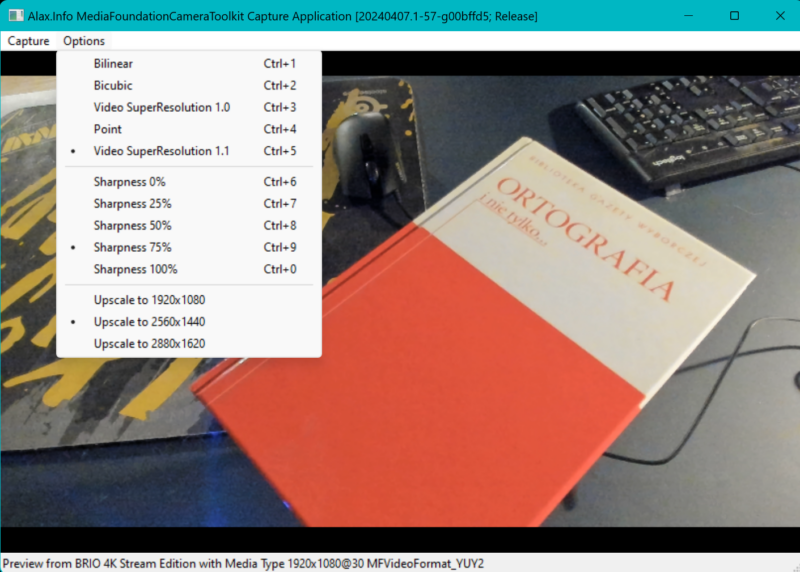
A variant of previous CaptureEngineVideoCapture demo application which features AMD Advanced Media Framework SuperResolution scaler for video.
It is basically a live video camera application started in low resolution mode, and it enables you to switch between GPU (OpenCL probably?) implemented realtime upscaling modes.
AMD scaler is wrapped into Media Foundation Transform and is applied to Microsoft Media Foundation Capture Engine as a video effect.
Note that SuperResolution 1.1 mode assumes upscaling in range 1.1 to 2.0 only and might not work if you select video resolution & target scaling resolution outside of the range.
The scaler is fast and fully GPU backed, perfect for real time, however the effect is not that obvious. Still it’s easy to see yourselves, just run and that’s it. Maybe next time I will do side by side, and then also DNN backed Media Foundation Transform to possibly address more expressive video output.
Also obviously it would help to dynamically change output resolution to be 1:1 with window size… It is also for the next experiment.